Reverse Engineering how WAFs Like Cloudflare Identify Bots
At IPM, we think about how automated bots manipulate tools intended for organic human use to steal infinite brownies, flood customer service teams, influence sticker-makers, and alter auction outcomes. One of the main tools employed against this type of behavior is the web application firewall (WAF). WAFs provide a perfunctory role in sophisticated bot prevention, however — in almost every case, they can be circumvented. But what the important factors in how people design bots to circumvent WAFs?
IPM recently sought to systematically analyze the response characteristics of WAFs in the face of bot traffic. We wanted to understand how different features of bot design influence whether or not bots are correctly identified as such. What follows below is a discussion of how several core features of bot design — IP obfuscation, browser environment obfuscation, virtualization, and headedness — are associated with whether or not WAFs correctly identify bot traffic, and the relative importance of each of those features.
For many folks, the current state of the art in defending against these security risks lies in the web application firewall, or the use of heuristics, AI, and other tools to reject requests based on cursory interrogations of those requests. Companies like Cloudflare, Human Security, Imperva, PerimeterX, and DataDome all provide services in this relatively mature industry. Faced with uncertainty about how to deal with bots, many folks opt to install these tools and assume that the problems of bots influencing behavior has been dealt with.
As we have shown in prior work, the current security landscape doesn’t do a great job of fully mitigating bot activity. At IPM, we regularly conduct tests to see what types of bot interfaces are able to reach their targets, and which ones are caught by mitigation techniques. At IPM, we currently maintain about 50 different bot “interfaces”, or distinct implementations of how bots may reach out into the internet. Each interface has a distinct combination of browser interface (e.g. Selenium vs. a HTTP library), network interface (e.g. direct from a cloud server, or re-routed through intermediary), and level of environment obfuscation (e.g. user agent manipulation). Jointly, these interfaces span a broad diversity of approaches that most bot makers are likely to explore when attempting to automate human behaviors on target sites.

Current IPM Bot Interface Deployment Offerings, along with whether or not they employ certain key features †
Recently, we showed that across nearly 200 top retailers, at least one of our roughly 50 bot interfaces was able to successfully reach the landing page of every single one. During that test, we generated 8,492 probe requests to 193 retailers across our 44 interfaces. In that work, we found that 61% of our requests successfully reached their target, while the rest were caught by web application firewalls built by the companies we listed above. Across our interfaces, we saw a wide success rate spectrum - some interfaces were successful only 10% of the time, while others reached their targets nearly 90% of the time.
Clearly, some bot designs are very easy to detect, and nearly all WAFs detect them. Other bot designs, however, employ many tricks to avoid detection and are largely successful at evading detection. So which features of bot design matter?
Each type of bot we run has certain characteristics that make it more or less easy to detect - do we try to hide the origin IP? Do we use a real browser instead of a basic HTTP library? Do we try to obfuscate the browser of origin’s environment? Do we run the browser on a virtual display? Each of our thousands of test pings against retailers had or lacked these characteristics, and were either caught or passed by WAF walls. If we aggregate all of those noisy tests, can we divine out some signal about what matters to WAF implementations today?
Of the 193 retailers we surveyed, we selected 96 retailers where WAFs caught at least 20% of our bot traffic. By making this selection, we omitted cases where any retailers were not employing WAFs in a substantial enough manner to conclude that they were making a concerted effort block this behavior in any intentional way. From this remaining set, we conducted a logistic regression along with factor analysis to determine which design feature matter most in circumventing WAFs.
For each request we sent, we coded them for whether that request obfuscated the IP of origin, obfuscated it’s default browser environment variables, employed a live browser environment, and whether or not that live browser environment was mounted to a virtual display (e.g. was running in a “headed” mode). We then ran a logistic regression employing those features as independent variables explaining the dependent variable of interest - did we get past the WAF wall or not?
In this model, the R^2, or amount of cases where we got through the WAF wall, explained by these four characteristics was 0.24, and the model was highly significant. Jointly, that’s enough to tell us that we are certainly measuring something substantively important about how WAFs detect bots, though by no means do we totally explain the story.
Due to tons of uncontrollable, stochastic behaviors both from our own bots as well as their responses to our bots, we can only hope to illustrate the probabilistic, relativistic importance of factors rather than being able to unambiguously say something like “just always use a proxy”. This is largely by design - if WAFs could be defeated by just a single rule or two, we’d likely already be well aware of them. Additionally, we’re considering multiple WAFs concurrently in this analysis, across a broad set of retailers, employing a potentially broad variety of WAF configurations - any clear signal under these circumstances is valuable.
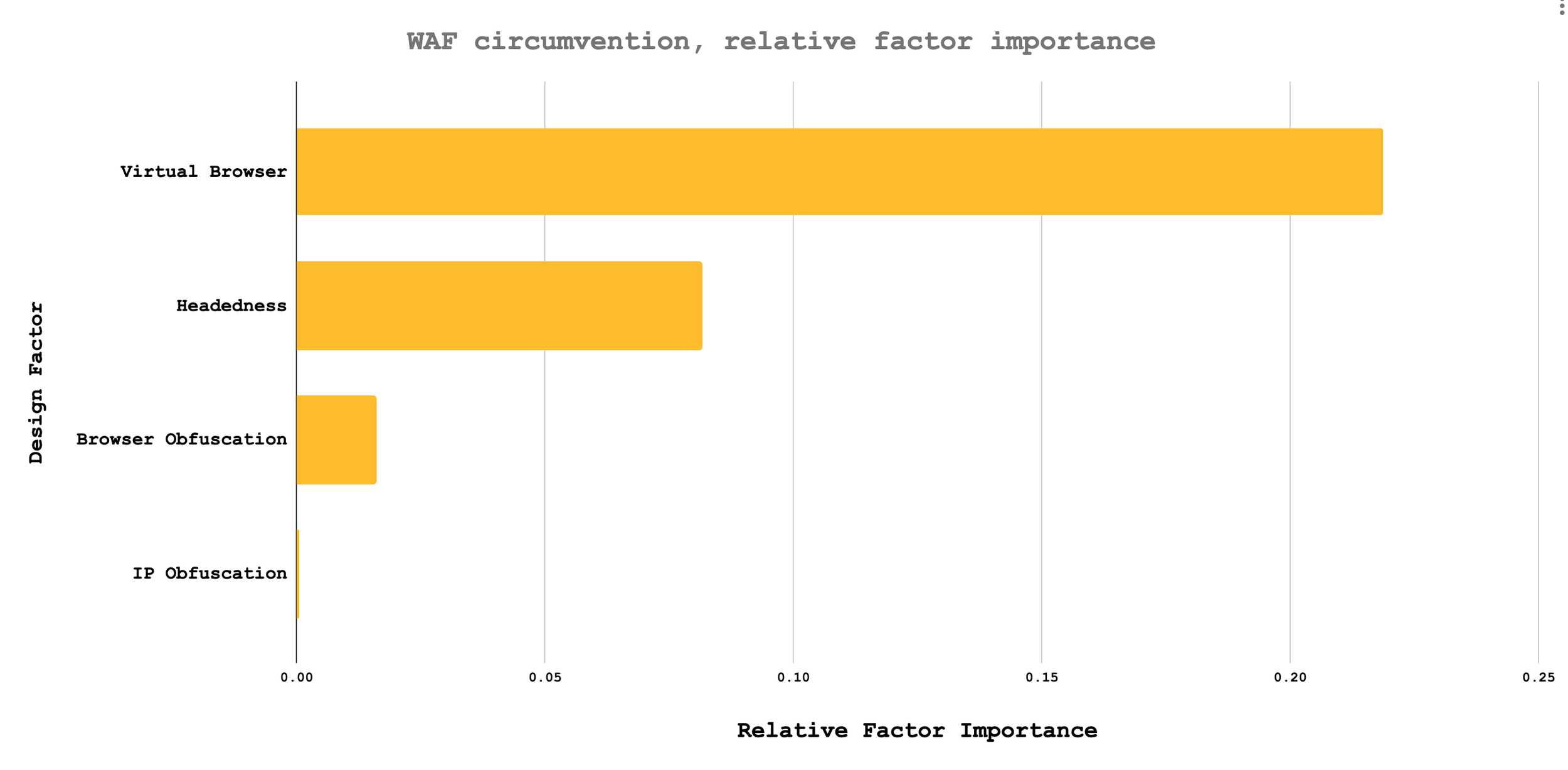
Relative Factor Loadings for how different design features of bots influence whether or not they'll circumvent WAFs
Clearly, the most important factor is whether or not a bot design implements browser virtualization (e.g. Selenium, Puppeteer, PhantomJS, and so forth). Distantly next is whether or not a virtual browser is mounted to a virtual display (i.e. runs in “headed” mode via XVFB). Distantly following that is whether or not the browser environment is intentionally attempting to obfuscate the browser’s settings (e.g. selenium-stealth, puppeteer-extra-plugin-stealth or undetected-chromedriver). Of almost no importance is whether or not the browser is obfuscating the traffic’s IP of origin by re-routing through VPNs, proxies, and the like.
To the trained practitioner, this is likely not too surprising. Even, then, the rank ordering and relative importance is instructive as a way to adjust the practitioner’s priors about what to focus energy on. When designing new bots, virtual browsers are the most effective first step, followed by headedness, followed by browser obfuscation, followed by IP obfuscation. When designing new attacks, a practitioner would be wise to work in that order to maximize their own time efficiency.
When designing interventions, the exact opposite ordering is valuable. WAF practitioners ought focus least on blocking by IP, since it’s not an important factor for getting through existing WAFs as it currently stands, for example. The most important place for WAF improvement is on figuring out solutions to disentangle virtual browsers from organic browsers.
The survey we ran against these top retailers, and the telemetric data we recovered from those probes, gives us a small view into the fundamental nature of how WAFs work today. Our model’s statistical and substantive significance gives us enough confidence that the view we’re seeing is truly reflecting some signal from the mass of noise. At IPM, we use this information to keep iterating on new browser interfaces that push the envelope further in terms of being able to approximate the very worst case designs that malicious bot-makers could use.
To learn more about how we can help you test your own WAFs mitigation capabilities, feel free to get in touch - to learn more about how we’re exploring the state of sociotechnical security, please refer to our other research.
† Selenium, Monitor and Incognito Icons by Freepik, Proxy icon by Creatype